Software is like nothing else in the history of human endeavor:1 unlike everything else we have ever built, software costs nothing to manufacture, and it never wears out. Yet these magical properties are arguably overshadowed by the ugly truth that software remains incredibly expensive to build. This gives rise to some strange economic properties: software’s fixed costs are high (very high — too high), but its variable costs are zero. As strange as they are, these economic properties aren’t actually unique to software; they are also true (to varying degree) of the products that we have traditionally called “intellectual property.” But unlike books or paintings or movies, software is predominantly an industrial good — it is almost always used as a component in a larger, engineered system. When you take these together — software’s role as an industrial good, coupled with its high fixed costs and zero variable costs — you get all sorts of strange economic phenomena. For example, doesn’t it strike you as odd that your operating system is essentially free, but your database is still costing you forty grand per CPU? Is a database infinitely more difficult to write than an operating system? (Answer: no.) If not, why the enormous pricing discrepancy?
I want to ultimately address the paradox of the software price discrepancy, but first a quick review of the laws of supply and demand in a normal market: at high prices, suppliers tend to want to supply more, while consumers tend to demand less; at low prices, consumers tend to demand more, while suppliers tend to want to supply less. We can show price versus quantity demanded/supplied with the classic supply and demand curves:
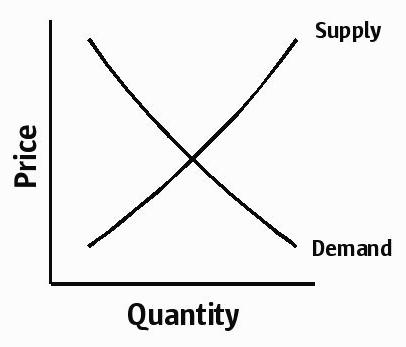
The point of intersection of the curves is the equilibrium price, and the laws of supply and demand tend to keep the market in equilibrium: as prices rise slightly out of equilibrium, suppliers will supply a little more, consumers will demand a little less, inventories will rise a little bit, and prices will fall back into equilibrium. Likewise, if prices fall slightly, consumers will demand a little more, inventories will become depleted, and prices will rise back into equilibrium.
The degree to which suppliers and consumers can react to prices — the slope of their respective curve — is known as price elasticity. In a price inelastic market, suppliers or consumers cannot react quickly to prices. For example, cigarettes have canonically high inelastic demand: if prices increase, few smokers will quit. (That said, demand for a particular brand of cigarettes is roughly normal: if Marlboros suddenly cost ten bucks a pack, cheap Russian imports may begin to look a lot more attractive.)
So that’s the market for smokes, but what of software? Let’s start by looking at the supply side, because it’s pretty simple: the zero variable cost means that suppliers can supply an arbitrary quantity at a given price. That is, this is the supply curve for software:
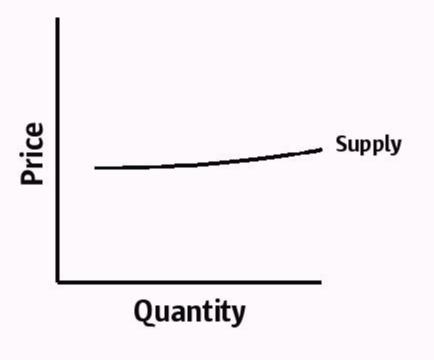
The height of the “curve” will be dictated by various factors: competitive environment, fixed costs, etc.; we’ll talk about how the height of this curve is set (and shifted) in a bit.
And what of the demand side? Software demand is normal to the degree that consumers have the freedom to choose software components. The problem is that for all of the rhetoric about software becoming a “commodity”, most software is still very much not a commodity: one software product is rarely completely interchangeable with another. The lack of interchangeability isn’t as much of an issue for a project that is still being specified (one can design around the specific intricacies of a specific piece of software), but it’s very much an issue after a project has deployed: deployed systems are rife with implicit dependencies among the different software components. These dependencies — and thus the cost to replace a given software component — tend to increase over time. That is, your demand becomes more and more price inelastic as time goes on, until you reach a point of complete price inelasticity. Perhaps this is the point when you have so much layered on top of the decision, that a change is economically impossible. Or perhaps it’s the point when the technical talent that would retool your infrastructure around a different product has gone on to do something else — or perhaps they’re no longer with the company. Whatever the reason, it’s the point after which the software has become so baked into your infrastructure, the decision cannot be revisited.
So instead of looking the nice supply and demand curves above, software supply and demand curves tend to look like this:
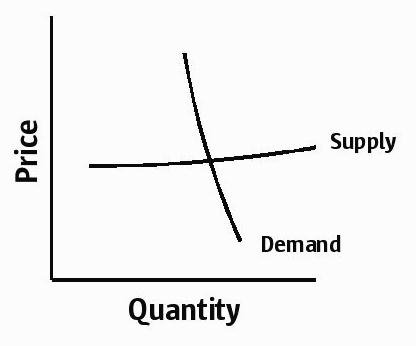
And of course, your friendly software vendor knows that your demand tends towards inelasticity — which is why they so frequently raise the rent while offering so little in return. We’ve always known about this demand inelasticity, we’ve just called it something else: vendor lock-in.
If software suppliers have such unbelievable pricing power, why don’t companies end up forking over every last cent for software? Because the demand for software isn’t completely price inelastic. It’s only inelastic as long as the price is below the cost of switching software. In the spirit of the FYO billboard on the 101, I dub this switching point the “FYO point”: it is the point at which you get so pissed off at your vendor that you completely reevaluate your software decision — you put everything back on the table. So here’s the completed picture:
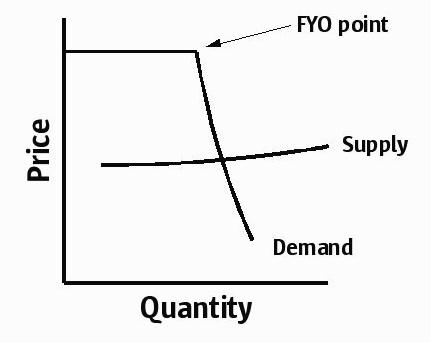
What happens at the FYO point? In extreme cases, you may decide to rewrite it yourself. Or maybe you’ll decide that it’s worth the pain to switch to a different (and less rapacious) vendor — or at least scaring your existing vendor to ease up a bit on their pricing. Or maybe you’ll ramp up a new project to replace the existing one, using all new components — thus normalizing your demand curve. And increasingly often, you decide that you’re not using half of the features of this thing anyway — and you start looking for a “good enough” open source option to get out of this ugly mess once and for all. (More on this later.)
Now, your software vendor doesn’t actually want you to hit the FYO point; they want to keep you far enough below it that you just sigh (or groan) and sign the check. (Which most of them are pretty good at, by the way — but of course, you already know that from all of your sighing and groaning.) There are essentially two ways for a software company to grow revenue on an established software product:
- Take away business from competitors
- Extract more dough out of existing customers
In terms of the FYO point, taking away competitors’ business amounts to lowering the FYO point of competitors’ customers. This can be done through technology (for example, by establishing open standards or developing migration tools) or it can be done through pricing (for example, by lowering the price they charge their competitors’ customers for their software — the “competitive upgrade”). This is a trend that generally benefits customers. If only there were no other option…
Sadly, there is another option, and most software companies opt for it: extracting more money from their existing customers. In terms of the FYO point, this amounts to raising the FYO point of their own customers. That is, software vendors act as a natural monopolist does: focusing their efforts not on competition, but rather on raising barriers to entry. They have all sorts of insidious ways of doing this: proprietary data formats, complicated interdependencies, deliberate incompatibilities, etc. Personally, I find these behaviors abhorrent, and I have been amazed about how brazen some software vendors are about maintaining their inalienable right to screw their own customers. To wit: I now have had not one but two software vendors tell me that I must add a way to disable DTrace for their app to prevent their own customers from observing their software. They’re not even worried about their competitors — they’re too busy screwing their own customers! (Needless to say, their requests for such a feature were, um, declined.)
So how does open source fit into this? Open source is a natural consequence of the economics of software, on both the demand-side and the supply-side. The demand-side has been discussed ad nauseum (and frequently, ad hominem): the demand for open source comes from customers who are sick of their vendors’ unsavory tactics to raise their FYO point — and they are sick more generally of the whole notion of vendor lock-in. The demand-side is generally responsible for customers writing their own software and making it freely available, or participating in similar projects in the community at large. To date, the demand-side has propelled much of open source software, including web servers (Apache) and scripting languages (Perl, Python). With some exception, the demand-side consists largely of individuals participating out of their interest more than their self-interest. As a result, it generally cannot sustain full-time, professional software developers.
But there’s also a supply-side to open source: if software has no variable cost, software companies’ attempts to lower their competitors’ customers’ FYO point will ultimately manifest itself in free software. And the most (if not the only) way to make software convincingly free is to make the source code freely available — to make it open source.2 The tendency towards open source is especially strong when companies profit not directly from the right-to-use of the software, but rather from some complementary good: support, services, other software, or even hardware. (In the specific case of Solaris and Sun, it’s actually all of the above.) And what if customers never consume any of these products? Well, the software costs nothing to manufacture, so there isn’t a loss — and there is often an indirect gain. To take the specific example of Solaris: if you run Solaris and never give a nickel to Sun, that’s fine by us; it didn’t even cost us a nickel to make your copy, and your use will increase the market for Solaris applications and solutions — driving platform adoption and ultimately driving revenue for Sun. To put this in retail terms, open source software has all of the properties of a loss-leader — minus the loss, of course.
While the demand-side has propelled much of open source to date, the supply-side is (in my opinion) ultimately a more powerful force in the long run: the software created by supply-side forces is generally been developed by people who do it full-time for a living — there is naturally a greater attention to detail. For a good example of supply-side forces, look at operating systems where Linux — the traditionally dominant open source operating system — has enjoyed profound benefits from the supply-side. These include contributions from operating systems such as AIX (JFS, scalability work), IRIX (XFS, observability tools and the occasional whoopsie), DYNIX/ptx (RCU locks), and even OS/2 (DProbes). And an even larger supply-side contribution looms: the open sourcing of Solaris. This will certainly be the most important supply-side contribution to date, and a recognition of the economics both of the operating systems market and of the software market more generally. And unlike much prior supply-side open source activity, the open sourcing of Solaris is not open source as capitulation — it is open source as counter-strike.
To come back to our initial question: why is the OS basically free while the database is costing you forty grand per CPU? The short answer is that the changes that have swept through the enterprise OS market are still ongoing in the database market. Yes, there have been traditional demand-side efforts like MySQL and research efforts like PostgreSQL, but neither of these “good enough” efforts has actually been good enough to compete with Informix, Oracle, DB/2 or Sybase in the enterprise market. In the last few years, however, we have seen serious supply-side movement, with MaxDB from SAP and Ingres from CA both becoming open source. Will either of these be able to start taking serious business away from Oracle and IBM? That is, will they be enough to lower the FYO point such that more customers say “FY, O”? The economics of software tells us that, in the long run, this is likely the case: either the demand-side will ultimately force sufficient improvements to the existing open source databases, or the supply-side will force the open sourcing of one of the viable competitors. And that software does not wear out and costs nothing to manufacture assures us that the open source databases will survive to stalk their competitors into the long run. Will this happen anytime soon? As Keynes famously pointed out, “in the long run, we are all dead” — so don’t count on any less sighing or groaning or check writing in the immediate future…
1 As an aside, I generally hate this rhetorical technique of saying that “[noun] is the [superlative] [same noun] [verb] by humankind.” It makes it sound like the chimps did this years ago, but we humans have only recently caught up. I regret using this technique myself, so let me clarify: with the notable exception of gtik2_applet2, the chimps have not yet discovered how to write software.
2 Just to cut off any rabid comments about definitions: by “open source” I only mean that the source code is sufficiently widely and publicly available that customers don’t question that its right-to-use is (and will always be) free. This may or may not mean OSI-approved, and it may or may not mean GPL. And of course, many customers have discovered that open source alone doesn’t solve the problem. You need someone to support it — and the company offering support begins to look, act and smell a lot like a traditional, rapacious software company. (Indeed, FYO point may ultimately be renamed the “FYRH point.”) You still need open standards, open APIs, portable languages and so on…
24 Responses
I studied Economics for 2 years, A-Levels as they’re called in the UK. Been a while since I last directly thought about things in terms of the laws of supplies and demand though. Very interesting post.
It’s interesting to think of your observations in terms of subscription software. In a way, the motivation behind this is to give the software supplier a more predictable and regular source of income. They no longer have to try to force their customers to upgrade regularly or do expenside add-on modules. This is particularly important for small, one-product vendors in small markets – eg EDA vendors. It just happens to increase lock-in too…
For client software, is it naturally harder or easier to migrate, I wonder? Particularly hard for OSs since one of the most critical points of OS choice is available (and supported) software. Not so much you can do in terms of migration tools either – user training and acceptance is a major issue. This is probably why Sun, and others, are concentrating on the “low hanging fruit” – customers with very old versions of Windows who want/need to migrate to something more modern. Such things cost a lot, and with the many changes from say Windows 95 (or NT-4) to Windows XP, user training and acceptance is going to be a major issue either way. Ditto for “productivity” software (Microsoft Office).
PS I don’t think software is quite at zero cost to “produce” yet – since bandwidth isn’t free. However, software like BitTorrent can help massively reduce bandwidth costs for distributing large files to many people. (it’s also nice in that it supports re-starts very well and does automatic checking of downloaded blocks and re-loads blocks that had transmission errors).
Thinking in supply and demand curves for software products is at least misleading. This economic model only works for commodities, which as you also said, does not apply to software. Treating software as commodities completely ignores the aspect of quality, which is of course very important (Compare Linux and Solaris!)
It also does not sufficiently explains, why databases are so much more expensive than operating systems. The database market is as old as the operating system market and has also seen several standardizations (POSIX, SQL, etc.).
In my opinion the reason for the different pricing is the knowledge distance between customer and vendor regarding software systems:
In case of operating systems the customers are also software developers or at least system admins, thus the distance is small. The vendor cannot charge an unreasonable high price, because the customer is competent in the domain of software products.
This is generally not the case with databases. They are often sold together with ERP systems and other “end user” software to companies outsde of the IT sector . These customers are more likely to accept high prices, because they do not have an extensive software background and market overview.
This is even truer for the speed of the migration from proprietary to open source software. ‘Software guys’ are much more inclined to test open source alternatives, because it is easier for them to work around problems and fix bugs.
Example:
You mentioned MaxDB (formerly SAPDB, in some sense it was SAP’s FYO-product).
Even though it is an excellent product and has been open source for some time (about 2000), it has not been widely deployed outside the SAP context. SAP even renamed the product(it now sails under the MySQL banner) to make it more attractive and well known.
The reason for this effect is the fact that most oracle customers do not even know or care about alternatives, because the software market is not transparent for ‘outsiders’!
Even worse for MaxDB, the name SAPDB suggested that it only works together with SAP systems…
Fortunately, a lak of acceptance will not be a problem for OpenSolaris. It is well know and respected and
I’m looking forward to building Solaris for a new platform, PowerPC or some embedded processor for example 😉
Ralf,
Microeconomic supply and demand curves are not limited to commodities. If supply for an good (commodity or otherwise) is constrained, while demand is high, a premium price can be charged. As an example, witness the new Apple iPod Mini. It has a regular selling price set by Apple, but when it first was released you could buy one of these and turn around and sell it for a significant premium.
Likewise, after the dot-com bust, the Sun SPARC/Solaris server market was flooded with previously owned Sun SPARC/Solaris servers, which significanlty depressed the economic price of newly manufactured versions of the same models sold directly by Sun and its reseller partners. This forced Sun to have to discount more, as well as engage in some of the behaviour Bryan mentioned to maintain lock in of Sun SPARC/Solaris servers purchased though legitimate channels.
Other visible examples of this occur in the auto industry. A new model of a vehicle can often fetch a premium, usually added by the dealer. I have personally seen the line item “Dealer Additional Profit” added to a popular new car model. Likewise, designs that are long in the tooth need additional rebates to make them more competitive, even though the competitor’s model is priced higher. The reason is microeconomic supply and demand curves typically only look at the supply and demand of a single good (i.e., Ford Taurus sedan vs. the whole 4-door sedan market, or Oracle database vs. the whole enterprise database market).
Interesting – I’d quibble rather more than a bit with some of the details of the analysis that Bryan uses, on theoretical grounds – his analysis confuses the market demand and supply curve (for perfect competition) and the individual firms’s profit maximising output levels. The former is where price is determined by the instersection of market Supply and Demand curves; in the latter, the profit maximising output of a firm facing a non competitive market (where because they don’t take the market price as given they face a downward sloping demand curve) profit maximising output is given by the intersection of marginal revenue (less than price) and marginal cost (zero in this case?) and the price they will be able to be charged will be greater than the marginal cost. In other words the intersection of supply and demand curves for a non-perfectly competitive firm will not determine the price and output… In other words the diagrams of price and output for the firm are plain wrong. I suspect that if I sat down and tried to work out what happens with a firm facing a kinked demand curve like this you would end up with something that gives discontinuous behaviour of the sort that Bryan suggests – but it doesn’t come because of the diagram he draws!
An example of a little knowlege of Economics being a dangerous thing…
Susan S.
Susan,
Despite the demand inelasticity, software isn’t a non-competitive market — quite the contrary given the presence of open source alternatives. Apologies if the analysis too often confuses the behavior of a single firm with one of a market, but I believe that the supply and demand curves do accurately represent the economics of software markets — where the FYO point is the point at which open source alternatives are actively considered. That said, I think your objection is trying to pigeon-hole the software market into preexisting micro analysis of the behavior of firms in non-competitive markets — an example of a little knowlege of Software being a dangerous thing…
If the market doesn’t follow the rules of **perfect** competiton ie identical products, perfect substitutes etc etc then simple demand and in particular supply curves cannot be used for the firm or the industry – if the firm doesn’t face a perfectly horizontal demand curve then talking about a supply curve for a firm is meaningless. You can certainly use the demand curve faced by the firm to analyse what will happen as the firm changes the price charged – and (as my first post didn’t make sufficiently clear) I have no problems with the shape of the demand curve that you propose; and indeed the discussion of complementarity is sensible and subject to my limited knowledge of the market explains what goes on reasonably well – but talking about a single supply curve just doesn’t make sense for anything other than perfect competition, which has a very specific set of requirements that the software market does not meet.
Susan S.
Susan, Thanks for clarifying your objection, and yes, that makes sense. I don’t think the supply curve plays too heavily into my analysis — my larger point is that the strange properties of software lead to unexpected results like firms giving away flagship products worth billions of dollars — but I can see that it would need to be factored out completely in a more rigorous analysis. That said, I would still put my economic analysis up against software written by an economist… 😉
I agree the supply curve is basically not a big part of the argument – however as a professional pedant I felt morally obliged to point out the error! I also figured that if you wanted to present the analysis in a more formal environment than a blog you would prefer to be aware that the diagrams were not strictly correct.
And no I don’t even pretend to write software… And most of the time I don’t believe economic analysis writen by other economsts either…
Susan S.
While I think the economic analysis was quite good, I do have to point out two things I disagree with, one of which I think is a flaw in your analysis.
First, you state that Open Source Software is a loss-leader without the loss, and you explain this by saying that Software is freely distributed, and that the loss is avoided thanks to the sale of complimentary goods. But in this paragraph, you only discuss the manufacture of software as its cost, and not its “build” cost, even though you included it in your great explanation of the costs of developing software. The build cost of software is where software companies take the finanical hit, and this is where I find the discussion about “cost” of open source software vs proprietary software falls apart. The Open Source proponents ignore it, while the prorietary software proponents go overboard with it.
Second, the complimentary goods model may not work well for all companies. Sun is a good example where it does work, since much of Sun’s revenue comes from hardware. It even makes sense for “pure” software companies like Microsoft, since they have other products they can sell for revenue, even if their platform is given away for free. But for smaller pure software companies that have only one or two products, it just doesn’t make any sense to release their product for free, as the revenue for complimentary products and services may not cover the total cost of production. They need to generate revenue to recuperate their initial invesment to produce the product, and that means selling the product.
Nat
Nat,
To address your first point:
remember, I’m referring only to the variable cost, not the total cost of the software. If one were to take that line alone, it would provide more context to say “open sourcing software is like selling a loss-leader” — that makes it clear that I’m talking about open sourcing existing software, not writing new software from scratch.
As to the second point, you’re absolutely correct: open sourcing proprietary software only works if one (a) has complementary goods
and (b) does not derive a significant amount of revenue from right-to-use.
As you point out, this makes it almost impossible for a small software company to consider. (But I think one could also argue that software from such companies is also less likely to be competitive with open source.) I imagine that Solaris may be seen as the canonical example where open sourcing makes sense: we have a huge number of complementary goods, we derive very little revenue from right-to-use, community and ecosystem are very important to us — and we’ve been getting our lunch eaten by open source competition. While our situation may not be common, it is by no means unique — and I expect it will become less rare over time.
I disagree that software does not wear out. While the statement itself is technically true, it’s misleading. As your second footnote points out, software needs to be maintained if it is to remain useful — new standards come out and new demands are made of the software. Without somebody footing the bill for the changes/enhancements that need to be made, the software quickly becomes useless even though it has not “worn out” in the same way mechanical devices do.
I second Paul’s comment. Software itself may not wear out, but the hardware that runs it will, at which point the software may not have any acceptable host environment. I’ve supported inter alia the SAPDB which is now MAXDB, and the worst problems were frequently related to hardware or OS upgrades. The db software itself is robust, but the environment in which it runs is not static. This produces the same effects as ‘wearing out’..
I stand by my statement: software does not wear out. That isn’t to say that software never breaks (or isn’t broken to begin with), but software that works can work in perpetuity. A favorite example of mine is troff. The source for troff is some of the nastiest stuff ever written — but it works. It hasn’t been touched in years, and probably will never be: it’s written in a portable language (C) and relies only on the most basic OS facilities. troff will work indefinitely — it will never wear out.
(The tragic footnote to troff is that its author, Joseph Ossanna, died tragically in 1977; the very fact that his software is humming along perfectly more than a quarter of a decade after his death is a testament to software’s unique imperviousness to wear.)
Hmm… interesting debate.
While I believe “code rot” exists, I also believe code can be used in production for a long long time.
I remember my mother telling me a few years ago that some payroll code she wrote 35 years ago was still in use (not much changed either apparantly). When I was a kid, we had a mainframe terminal in the house, so my mother could work from home. The concept behind Sun Ray @ Home is pretty obvious to me ^-^
I have some Perl tools that I use regularly on multiple platforms that I haven’t changed in about 6 years.
There’s certainly a lot of scope for code “rotting” over time – backwards compatability issues in the OS, compiler, middleware or whatever. Which is of course affected by how solid the code is in the first place, how much it depends on OS features and libraries, and how paranoid the vendors are about backwards compatability. Strict, extensive and heavily automated bug and regression testing can certainly go a long way to help. I think maintaining backwards compatability should be the equivalent of “first, do no harm” for doctors.
Maybe another way to put it is that (a particular version of) code does not die of natural causes – it is either slowly poisoned (poor management/maintenance, lack of backwards compatability) or murdered (by vendors wanting to force an upgrade, or cut their losses).
That’s a great way of phrasing it Chris: software doesn’t die of old age, but that doesn’t mean that it doesn’t die. Interesting, too, about the code your mom wrote — and not at all surprising. I was visiting with a senior IT architect at a very (very!) large bank in late 2000. He told me that over forty percent of their Y2K problems came from a single platform: the IBM 1401! He said that this code was running in a 1401 emulator written for the IBM 360, which in turn was running in a 360 emulator on modern hardware. This was software written moments after the dawn of software — and here it was, still plugging away in production. And even with Y2K, it was apparently cheaper to find the geezers who still knew 1401 assembler and pay them to fix the problem that it was to reimplement the software. And so that software lives on — to 2038 and beyond!
Brian, that “old code” example is pretty scary!
Hmm… I seem to remember some comments in the SCO/Linux case about some code that supposedly got stolen from SCO. I think some of the examples were actually for ancient (25-30 year old) Unix code! Comments and all.
PS Just sent you an email regarding Dtrace (since it’d be rather off-topic here).
[Trackback] Interessanter Artikel zur Softwareindustrie : The Observation Deck.
[Trackback] Apparently, engineers over at Sun are given a special space to post their blogs. Its interesting that the suits at Sun would allow their employees to post on a public blog–opens up possibilities legal entanglements. But thats not the real…
Bryan, you mention troff as software that hasn’t worn out. But the link goes to a blog which includes the comment:
“The scary thing is that there are at least 18 bugs in our database open against nroff or troff; one of the side-effects of promising full backwards compatibility.”
Not exactly ‘humming along perfectly’.. heh. ahem. Sorry.
I do remember in Comp Sci 101, in 1977, being told that Cobol and Fortran weren’t going to be very useful except for learning about programming. Here we are in the new milleniumn, and I’m still helping customers with Cobol code, even exposing Cobol programmes as web services..
not sure if troff is really a good example. the version you think is <em>humming along</em> was put together by brian kernighan; ossanna version was displaced a long time ago (for a while kept under the name otroff) with brian’s version because making it drive anything other than a C/A/T was such a pain.it had many other limitations and problems, which is why brian also did ditroff. [see cstr #97 for all the gory details. one could argue especially for troff that it <em>did</em> wear out, in more ways than one…]
[Trackback] Well it’s almost a month later, and I still haven’t finished my article on software economics. I’ve been busy, as always, but I’ve also had some recent changes in my job that have been distracting me. More on those job changes tomorrow.
But since I …
[Trackback] This is the second part of my follow up to Bryan Catrill’s post about software economics . The first part of my follow up can be found in an earlier post .
Part Two: The Real Cost of Delivering Software
Both part one of my follow up and Bry…
“Software is like nothing else in the history of human endeavor:1 unlike everything else we have ever built, software costs nothing to manufacture, and it never wears out”
Hi Bryan.
I didn’t even read past the first sentence because it spacked of a shallow treatment.
(so you can do the same here 🙂
Software obviously does wear out. There is software that is now unusable. That’s because the environment for it changes. Even if the feature set is fixed, the environment is not stable. You could have explored why that becomes true.
If software is no longer used, it is worn out.
My definition.
Software does have manufacturing costs. For one, there is no such thing as shrink-wrapped software. User’s demand support. User’s demand bug fixes. All manufacturing has a minimal amount of costs, because of the presence of lawsuits when the promised functionality doesn’t exist, or damage is created.
Your model of costs is silly. MSFT doesn’t just flush money down toilets, nor does SUNW. It gets spent on stuff, that if unspent, means the software doesn’t get purchased by users.
So all you have, is something with different manufacturing costs, and a different set of criteria for determining it’s wearout period.
You can bring it down to the simplest model. A single person writing software in his home, distributing it over the ‘net. There are costs there also. And eventually, if nothing changes,
people will stop using that software.
I can find a nail from 1850 that’s still usable.
So if you find some junk software that’s still usable, i’m not sure it means much in the bigger
argument.
Brilliant article. Kudos to you, Bryan!