I come to bury SPEC SFS, not to praise it.
When we at Fishworks set out, our goal was to build a product that would disrupt the enterprise NAS market with revolutionary price/performance. Based on the economics of Sun’s server business, it was easy to know that we would deliver on the price half of that promise, but the performance half promised to be more complicated: while price is concrete and absolute, the notion of performance fluctuates with environment, workload and expectations. To cut through these factors, computing systems have long had their performance quantified with benchmarks that hold environment and workload constant, and as we began to learn about NAS benchmarks, one in particular loomed large among the vendors: SPEC‘s system file server benchmark, SFS. Curiously, the benchmark didn’t come up much in conversations with customers, who seemed to prefer talking about raw capabilities like maximum delivered read bandwidth, maximum delivered write bandwidth, maximum synchronous write IOPS (I/O operations per second) or maximum random read IOPS. But it was clear that the entrenched NAS vendors took SPEC SFS very seriously (indeed, to the point that they seemed to use no other metric to describe the performance of the system), and upstarts seeking to challenge them seemed to take it even more seriously, so we naturally assumed that we too should use SPEC SFS as the canonical metric of our system…
But as we explored SPEC SFS — as we looked at the workload that it measures, examined its run rules, studied our rivals’ submissions and then contrasted that to what we saw in the market — an ugly truth emerged: whatever connection to reality it might have once had, SPEC SFS has long since become completely divorced from the way systems are actually used. And worse than simply being outdated or irrelevant, SPEC SFS is so thoroughly misguided as to implicitly encourage vendors to build the wrong systems — ones that are increasingly outrageous and uneconomic. Quite the opposite of being beneficial to customers in evaluating systems, SPEC SFS has decayed to the point that it is serving the opposite ends: by rewarding the wrong engineering decisions, punishing the right ones and eliminating price from the discussion, SPEC SFS has actually led to lower performing, more expensive systems! And amazingly, in the update to SPEC SFS — SPEC SFS 2008 — the benchmark’s flaws have not only gone unaddressed, they have metastasized. The result is such a deformed monstrosity that — like the index case of some horrific new pathogen — its only remaining utility lies on the autopsy table: by dissecting SPEC SFS and understanding how it has failed, we can seek to understand deeper truths about benchmarks and their failure modes.
Before taking the scalpel to SPEC SFS, it is worth considering system benchmarks in the abstract. The simplest system benchmarks are microbenchmarks that measure a small, well-defined operation in the system. Their simplicity is their great strength: because they boil the system down to its most fundamental primitives, the results can serve as a truth that transcends the benchmark. That is, if a microbenchmark measures a NAS box to provide 1.04 GB/sec read bandwidth from disk, then that number can be considered and understood outside of the benchmark itself. The simplicity of microbenchmarks conveys other advantages as well: microbenchmarks are often highly portable, easily reproducible, straightforward to execute, etc.
Unfortunately, systems themselves are rarely as simple as their atoms, and microbenchmarks are unable to capture the complex interactions of a deployed system. More subtly, microbenchmarks can also lead to the wrong conclusions (or, worse, the wrong engineering decisions) by giving excessive weight to infrequent operations. In his excellent article on performance anti-patterns, my colleague Bart Smaalders discussed this problem with respect to the getpid system call. Because measuring getpid has been the canonical way to measure system call performance, some operating systems have “improved” system call performance by turning getpid into a library call. This effort is misguided, as are any decisions based on the results of measuring it: as Bart pointed out, no real application calls getpid frequently enough for it to matter in terms of delivered performance.
Making benchmarks representative of actual loads is a more complicated undertaking, with any approach stricken by potentially serious failings. The most straightforward approach is taken by application benchmarks, which run an actual (if simplified) application on the system, and measure its performance. This approach has the obvious advantage of measuring actual, useful work — or at least one definition of it. This means, too, that system effects are being taken into consideration, and that one can have confidence that more than a mere back eddy of the system is being measured. But an equally obvious drawback to this approach is that it is only measuring one application — an application which may not be at all representative of a deployed system. Moreover, because the application itself is often simplified, application benchmarks can still exhibit the microbenchmark’s failings of oversimplification. From the perspective of storage systems, application benchmarks have a more serious problem: because application benchmarks require a complete, functional system, they make it difficult to understand and quantify merely the storage component. From the application’s perspective, the system is opaque; who is to know if, say, an impressive TPC result is due to the storage system rather than more mundane factors like, say, database tuning?
Synthetic benchmarks address this failing by taking the hybrid approach of deconstructing application-level behavior into microbenchmark-level operations that they then run in mix that matches the actual use. Ideally, synthetic benchmarks combine the best of both variants: they offer the simplicity and reproducibility of the microbenchmarks, but the real-world applicability of the application-level benchmarks. But beneath this promise of synthetic benchmarks lurks an opposite peril: if not executed properly, synthetic benchmarks can embody the worst properties of both benchmark variants. That is, if a synthetic benchmark combines microbenchmark-level operations in a way that does not in fact correspond to higher level behavior, it has all of the complexity, specificity and opacity of the worst application-level benchmarks — with the utter inapplicability to actual systems exhibited by the worst microbenchmarks.
As one might perhaps imagine from the foreshadowing, SPEC SFS is a synthetic benchmark: it combines NFS operations in an operation mix designed to embody “typical” NFS load. SPEC SFS has evolved over more than a decade, having started life as NFSSTONE and then morphing into NHFSSTONE (ca. 1992) and then LADDIS (a consortium of Legato, Auspex, DEC, Data General, Interphase and Sun) before become a part of SPEC. (As an aside, “LADDIS” is clearly BUNCH-like in being a portent of a slow and miserable death — may Sun break the curse!) Here is the NFS operation mix for SPEC SFS over its lifetime:
| NFS operation |
SFS 1.1 (LADDIS) |
SFS 2.0/3.0 (NFSv2) |
SFS 2.0/2.3 (NFSv3) |
SFS 2008
|
| LOOKUP
| 34%
| 36%
| 27%
| 24%
|
| READ
| 22%
| 14%
| 18%
| 18%
|
| WRITE
| 15%
| 7%
| 9%
| 10%
|
| GETATTR
| 13%
| 26%
| 11%
| 26%
|
| READLINK
| 8%
| 7%
| 7%
| 1%
|
| READDIR
| 3%
| 6%
| 2%
| 1%
|
| CREATE
| 2%
| 1%
| 1%
| 1%
|
| REMOVE
| 1%
| 1%
| 1%
| 1%
|
| FSSTAT
| 1%
| 1%
| 1%
| 1%
|
| SETATTR
| –
| –
| 1%
| 4%
|
| READDIRPLUS
| –
| –
| 9%
| 2%
|
| ACCESS
| –
| –
| 7%
| 11%
|
| COMMIT
| –
| –
| 5%
| N/A
|
The first thing to note is that the workload hasn’t changed very much over the years: it started off being 58% metadata read operations (LOOKUP, GETATTR, READLINK, READDIR, READDIRPLUS, ACCESS), 22% read operations and 15% write operations, and it’s now 65% metadata read operations, 18% read operations and 10% write operations. So where did that original workload come from? From an unpublished study at Sun conducted in 1986! (I recently interviewed a prospective engineer who was not yet born when this data was gathered — and I’ve always thought it wise to be wary of data older than oneself.) The updates to the operation mix are nearly as dubious: according to David Robinson’s thorough paper on the motivation for SFS 2.0, the operation mix for SFS 3.0 was updated based on a survey of 750 Auspex servers running NFSv2 — which even at the time of that paper’s publication in 1999 must have elicited some cocked eyebrows about the relevance of workloads on such clunkers. And what of the most recent update? The 2008 reaffirmation of the decades-old workload is, according to SPEC, “based on recent data collected by SFS committee members from thousands of real NFS servers operating at customer sites.” SPEC leaves unspoken the uncanny coincidence that the “recent data” pointed to an identical read/write mix as that survey of those now-extinct Auspex dinosaurs a decade ago — plus ça change, apparently!
Okay, so perhaps the operation mix is paleolithic. Does that make it invalid? Not necessarily, but this particular operation mix does appear to be something of a living fossil: it is biased heavily towards reads, with a mere 15% of operations being writes (and a third of these being metadata writes). While I don’t doubt that this is an accurate snapshot of NAS during the Reagan Administration, the world has changed quite a bit since then. Namely, DRAM sizes have grown by nearly five orders of magnitude (!), and client caching has grown along with it — both in the form of traditional NFS client caching, and in higher-level caching technologies like memcached or (at a larger scale) content distribution networks. This caching serves to satisfy reads before they ever make it to the NAS head, which can leave the NAS head with those operations that cannot be cached, worked around or generally ameliorated — which is to say, writes.
If the workload mix is dated because it does not express the rise of DRAM as cache, one might think that this would also shine through in the results, with systems increasingly using DRAM cache to achieve a high SPEC SFS result. But this has not in fact transpired, and the reason it hasn’t brings us to the first fatal flaw of SPEC SFS: instead of making the working set a parameter of the benchmark — and having a result be not a single number but rather a graph of results given different working set sizes — the working set size is dictated by the desired number of operations per second. In particular, in running SPEC SFS 3.0, one is required to have ten megabytes of underlying filesystem for every operation per second. (Of this, 10% is utilized as the working set of the benchmark.) This “scaling rule” is a grievous error, for it diminishes the importance of cache as load climbs: in order to achieve higher operations per second, one must have larger working sets — even though there is absolutely no reason to believe that such a simple, linear relationship exists in actual workloads. (Indeed, in my experience, if anything the opposite may be true: those who are operation intensive seem to have smaller working sets, not larger ones — and those with larger amounts of data tend to focus on bandwidth more than operations per second.)
Interestingly, when this scaling rule was established, it was done so with some misgivings. According to David Robinson’s paper (emphasis added):
From the large file set created, a smaller working set is chosen for actual operations. In SFS 1.0 the working set size was 20% of file set size or 1 MB per op/sec. With the doubling of the file set size in SFS 2.0, the working set was cut in half to 10% to maintain the same working set size. Although the amount of disk storage grows at a rapid rate, the amount of that storage actually being accessed grows at a much slower rate. [ … ] A 10% working set size may still be too large. Further research in this area is needed.
David, at least, seems to have been aware that this scaling rule was specious even a decade ago. But if the scaling rule was suspect in the mid-1990s, it has became absurd since. To see why, take, for example, NetApp’s reasonably recent result of 137,306 operations per second. Getting to this number requires 10 MB per op/sec, or about 1.3 TB. Now, 10% of this — or about 130GB — will be accessed over the course of the benchmark. The problem is that from the perspective of caching, the only hope here is to cache metadata, as the data itself exceeds the size of cache and the data access pattern is essentially random. With the cache effectively useless, the engineering problem is no longer designing intelligent caching architectures, but rather designing a system that can quickly serve data from disk. Solving the former requires creativity, trade-offs and balance — but solving the latter just requires brute force: fast drives and more of ’em. And in this NetApp submission, the force is particularly shock-and-awe: not just 15K RPM drives, but a whopping 224 144GB 15K RPM drives — delivering 32TB of raw capacity for a mere 1.3TB filesystem. Why would anyone overprovision storage by a factor of 20? The answer is that with the filesytem presumably designed to allocate from outer tracks before inner ones, allocating only 5% of available capacity guarantees that all data will live on those fastest, outer tracks. This practice — so-called short-stroking — means both faster transfers and minimal no head movement, guaranteeing that any I/O operation can be satisfied in just the rotational latency of a 15K RPM drive.
Short-stroking 224 15K RPM drives is the equivalent of fueling a dragster with nitromethane — it is top performance at a price so high as to be useless off the dragstrip. It’s a safe bet that if one actually had this problem — if one wished to build a system to optimize for random reads within a 130GB working set over a total data set of 1.3TB — one would never consider such a costly solution. How, then, would one solve this particular problem? Putting the entire data set on flash would certainly become tempting: an all flash-based solution is both faster and cheaper than the fleet of nitro-belching 15K RPM drives. But if this is so, does it mean that the future of SFS is to be flash-based configurations vying for king of an increasingly insignificant hill? It might have been so were in not for the revisions in SPEC SFS 2008: the scaling rule has gone from absurd to laughably ludicrous, as what used to be 10MB per op/sec, is now 120MB per op/sec. And as if this recklessness were not enough, the working set ratio has additionally been increased from 10% to 30% of total storage. One can only guess what inspired this descent into madness, but the result is certainly insane: to achieve this same 137,306 ops will require a 17TB filesystem — of which an eye-watering 5TB will be hot! This is nearly a 40X increase in working set size, without (as far as I can tell) any supporting data. At best, David’s warning that the scaling rule may have been excessive has been roundly ignored; at worst, the vendors have deliberately calculated how to adjust the problem posed by the benchmark such that thousands of 15K RPM drives remain the only possible solution, even in light of new technologies like flash. But it’s hard to know for sure which case SPEC has fallen into: the decision to both increase the scaling rule and increase the working set ratio is so terrible that incompetence becomes indistinguishable from malice.
Be it due to incompetence or malice, SPEC’s descent into a disk benchmark while masquerading as a system benchmark does worse than simply mislead the customer, it actively encourages the wrong engineering decisions. In particular, as long as SPEC SFS is thought to be the canonical metric of NFS performance, there is little incentive to add cache to NAS heads. (If SPEC SFS isn’t going to use it, why bother?) The engineering decisions made by the NAS market leaders reflect this thinking, as they continue to peddle grossly undersized DRAM configurations — like NetApp’s top-of-the-line FAS6080 and its meager maximum of 32GB of DRAM per head! (By contrast, our Sun Storage 7410 has up to 128GB of DRAM — and for a fraction of the price, I hasten to add.) And it is of no surprise that none of the entrenched players conceived of the hybrid storage pool; SPEC SFS does little to reward cache, so why focus on it? (Aside from the fact that it delivers much faster systems, of course!)
While SPEC SFS is hampered by its ancient workload and made ridiculous by its scaling rule, there is a deeper and more pernicious flaw in SPEC SFS: there is no pricing disclosure. This flaw is egregious, unconscionable and inexcusable: as the late, great Jim Gray made clear in his classic 1985 Datamation paper, one cannot consider performance in a vacuum — when purchasing a system, performance must be considered relative to price. Gray tells us how the database community came to understand this: in 1973, a bank received two bids for a new transaction system. One was for $5M from a mini-computer vendor (e.g. DEC with its PDP-11), the other for $25M from a traditional mainframe vendor (presumably IBM). The solutions offered identical performance; the fact that there was a 5X difference in price (and therefore price/performance), “crystallized” (in Gray’s words) the importance of price in benchmarking — and Gray’s paper in turn enshrined price as an essential metric of a database system. (Those interested in the details of the origins Gray’s iconoclastic Datamation paper and the long shadow that it has cast are encouraged to read David DeWitt and Charles Levine’s excellent retrospective on Gray’s work in database performance.) Today, the TPC benchmarks that Gray inspired have pricing at their heart: each submission is required to have a full disclosure report (FDR) that must include the price of the system and everything that that price includes, including part numbers and per-part pricing. Moreover, the system must be orderable: customers must be able to call up the vendor and demand the specified config at the specified price. This is a beautiful thing, because TPC allows for competition not just on performance (“TpmC” in TPC parlance) but also price/performance ($/TpmC). And indeed, in the 1990s, this is exactly what happened as low $/TpmC submissions from the likes of SQLServer running on Dell put competitive pressure on vendors like Sun to focus on price/performance — with customers being the clear winners in the contest.
By contrast, SPEC SFS’s absence of a pricing disclosure forbids competitors from competing on price/performance, instead encouraging absolute performance at any cost. This was taken to the logical extreme with NetApp and their preposterous 1,032,461 result — which took but 2,016 short-stroked 15K RPM drives! Steven Schwartz took NetApp to task for the exorbitance of this configuration, pointing out that NetApp’s configuration was a factor two to four times more expensive on a per-op basis than competitive results in his blog entry aptly titled “Benchmarks – Lies and the Lying Liars Who Tell Them.”
But are lower results any less outrageous? Take again that NetApp config. We don’t know how much that 3170 and its 224 15K RPM drives will cost you because NetApp isn’t forced to disclose it, but suffice it to say that it’s quite a bit — almost certainly seven figures undiscounted. But for the sake of argument, let’s assume that you get a steep discount and you somehow get this clustered, racked-out config to price out at $500K. Even then, given the meager 1.3TB delivered for purposes of the benchmark, this system costs an eye-watering $384/GB — which is about 8X more expensive than DRAM! So even in the unlikely event that your workload and working set match SPEC SFS, you would still be better off blowing your wallet on a big honkin’ RAM disk than buying the benchmarked configuration. And this embodies the essence of the failings of SPEC SFS: the (mis)design of the benchmark demands economic insanity — but the lack of pricing disclosure conceals that insanity from the casual observer. The lesson of SPEC SFS is therefore manifold: be skeptical of a system benchmark that is synthetic, be suspicious of a system benchmark that lacks a price disclosure — and be damning when they are one and the same.
With the SPEC SFS carcass dismembered and dispensed with, where does this leave Fishworks and our promise to deliver revolutionary price/performance? After considering SPEC SFS (and rejecting it, obviously), we came to believe that the storage benchmark well was so poisioned that the best way to demonstrate the performance of the product would be simple microbenchmarks that customers could run themselves — which had the added advantage of being closer to the raw capabilities that customers wanted to talk about anyway. In this spirit, see, for example, Brendan’s blog entry on the 7410’s performance limits. Or, if you’re more interested in latency than bandwidth, check out his screenshots of the L2ARC in action. Most importantly: don’t take our word for it — get one yourself, run it with your workload, and then use our built-in analytics to understand not just how the system runs, but also why. We have, after all, designed our systems to be run, not just to be sold…
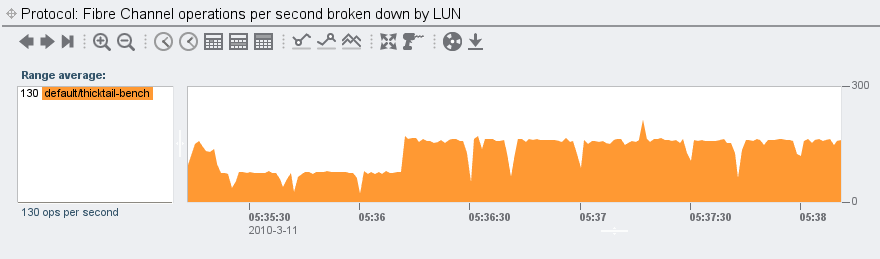
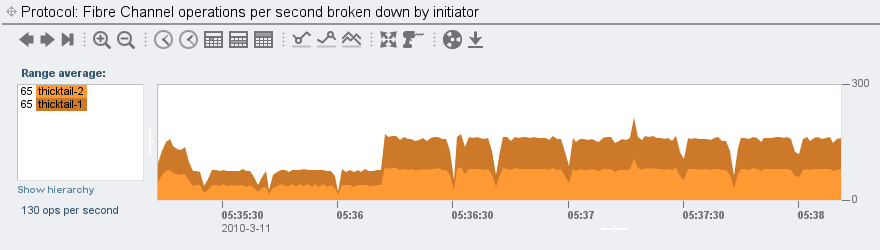
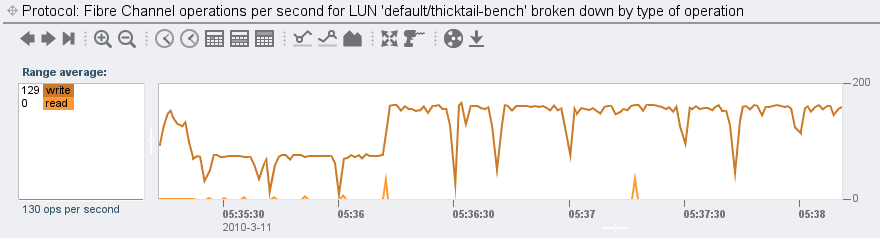
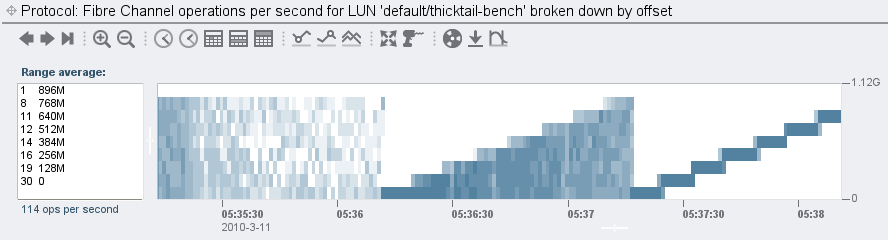
 Second, has anyone ever accused the enterprise storage vendors of dropping their prices in pace with these laws — or even abiding by them in the first place? The last time I checked, the single-core Mobile Celeron that NetApp currently ships in their FAS2020 and FAS2050 — a CPU with a criminally small 256K of L2 cache — is best described as a Moore’s Outlaw: a CPU that, even when it first shipped six (six!) years ago, was off the curve. (A single-core CPU with 256K of L2 cache was abiding by Moore’s Law circa 1997.) Though it’s no wonder that NetApp sees plummeting component costs when they’re able to source their CPUs by dumpster diving…
Second, has anyone ever accused the enterprise storage vendors of dropping their prices in pace with these laws — or even abiding by them in the first place? The last time I checked, the single-core Mobile Celeron that NetApp currently ships in their FAS2020 and FAS2050 — a CPU with a criminally small 256K of L2 cache — is best described as a Moore’s Outlaw: a CPU that, even when it first shipped six (six!) years ago, was off the curve. (A single-core CPU with 256K of L2 cache was abiding by Moore’s Law circa 1997.) Though it’s no wonder that NetApp sees plummeting component costs when they’re able to source their CPUs by dumpster diving…