libumem was developed in 2001 by Jeff Bonwick and Jonathan Adams. While the Solaris implementation of malloc(3C) and free(3C) performed adequately for single threaded applications, it did not scale. Drawing on the work that was done to extend the original kernel slab allocator, Jeff and Jonathan brought it to userland in the form of libumem. Since then, libumem has even been brought to other operating systems. libumem offers great performance for multi-threaded applications, though there are a few cases where libumem doesn’t quite perform compared to libc and the allocators found in other operating systems like eglibc. The most common case for this is when you have short-lived small allocations, often less than 200 bytes.
What’s happening?
As part of our work with Voxer, they had uncovered some general performance problems that Brendan and I were digging into. We distilled this down to a small Node.js benchmark that was calculating a lot of md5 sums. As part of narrowing down the problem, I eventually broke out one of Brendan’s flame graphs. Since we had a CPU-bound problem, this allowed us to easily visualize and understand what’s going on. When you throw that under DTrace with jstack(), you get something that looks pretty similar to the following flame graph:

There are two main pieces to this flame graph. The first is performing the actual md5 operations. The second is creating and destroying the md5 objects and the initialization associated with that. In drilling down, we found that we were spending comparatively more time trying to handle the allocations. If you look at the flamegraph in detail, you’ll see that when calling malloc and free we’re spending a lot of that time in in the lock portions of libc. libc’s malloc has a global mutex. Using a simple DTrace script like dtrace -n 'pid$target::malloc:entry{ @[tid] = count(); }', we can verify that only one thread is calling into malloc, so we’re grabbing an uncontended lock. One’s next guess might be to try and run this with libumem to see if there is any difference. This gives us the following flame graph:

You can easily spot all of the libumem related allocations because they are a bit more like towers that consist of a series of three functions calls. First to malloc(3C), then umem_alloc(3MALLOC), and finally umem_cache_alloc(3MALLOC). On top of that are additional stacks related to grabbing locks. In umem_cache_alloc there is still a lock that a thread has to grab. Unlike libc’s malloc, this lock is not a global lock. Each cache has a lock per-CPU, which, when combined with magazines allows for highly-parallel allocations. However, we’re only doing mallocs from one thread so this is an uncontested mutex lock. The key takeaway from this is that the uncontested mutex lock can still be problematic. This is also much trickier in user-land where there is a lot more to deal with when grabbing a lock. Compare the kernel implementation with the user-land implementation. One conclusion that you reach from this is that we should do something to get rid of the lock.
When getting rid of mutexes, one might first think of using atomics and trying to rewrite this to be lock-free. But, aside from the additional complexity that rewriting portions of this to be lock-free might induce, that doesn’t solve the fundamental problem: we don’t want to be synchronizing at all. Instead this suggests a different idea that other memory allocators have taken: adding a thread-local cache.
A brief aside: libumem and malloc design
As part of libumem’s design it creates a series of fixed size caches which it uses to handle allocations. These caches are sized from 8 bytes to 128KB, with the difference between caches growing larger with the cache size. If a malloc comes in that is within the range of one of these caches then we use the cache. If the allocation is larger than 128KB then libumem uses a different means to allocate that. For the rest of this entry we’ll only talk about the allocations that are handled by one these caches. For the full details of libumem, I strongly suggest you read the two papers on libumem and the original slab allocator.
Keeping track of your allocations
When you call malloc(3C) you pass in a size, but you don’t need to pass that size back into free(3C). You only need to pass in the buffer. malloc ends up doing work to handle this for you. malloc will actually allocate an extra eight byte tag and prepend that to the buffer. So if you request a 36 bytes, malloc will actually allocate 42 bytes from the system and return you a pointer that starts right after that tag. This tag encodes two pieces of information. The first piece is the size and the second piece is a tag that is encoded with the size. It uses the second field to help detect programs that erroneously write to memory. The structure that it prepends looks like:
typedef struct malloc_data {
uint32_t malloc_size;
uint32_t malloc_stat;
} malloc_data_t;
When you call free, libumem grabs that structure, reads the buffer size, and validates the tag. If everything checks out, it releases the entire buffer back to the appropriate cache. If it doesn’t check out, libumem aborts the program.
Per-Thread Caching: High-level
To speed up the allocation and free process, we’re going to change how malloc and free work. When a given thread calls free, instead of releasing the buffer directly back to the cache, we will instead store it with the thread. That way if the thread comes around and requests a buffer that would be satisfied by that cache, it can just take the one that it stored. By creating this per-thread cache, we have a lock-free and contention-free means of servicing allocations. We store these allocations as a linked list and use one list per cache. When we want to add a buffer to the list, we make it the new head. When we remove an entry from the list, we remove the head. If the head is set to NULL then we know that the list is empty. When the list is empty, we simply go ahead and use the normal allocation path. When a thread exits, then all of the buffers in that thread are freed back to the underlying caches.
We don’t want the per-thread cache to end up storing an unbounded amount of memory. That would end up appearing no different from a memory leak. Instead, we have two mechanisms in place to control this.
- A cap on the amount of memory each thread may cache.
- We only enable this for a subset of umem caches.
By default, each thread is capped at 1 MB of cache. This can be configured on a per process basis using the UMEM_OPTIONS environment variable. Simply set perthread_cache=[size]. The size is in bytes and you can use the common K, M, G, and even T, suffixes. We only support doing this for sixteen caches at this time and we opt to make this the first sixteen caches. If you don’t tune the cache sizes, allocations up to 256 bytes for 32-bit applications and up to 448 bytes for 64-bit applications will be cached.
Finally, when a thread exits, all of the memory in that thread’s cache is released back to the underlying general purpose umem caches.
Another aside: Position Independent Code
Modern libraries are commonly built with Position Independent Code (PIC). The goal of building something PIC is that it can be loaded anywhere in the address space and no additional relocations will need to be performed. This means that all the offsets and addresses within a given library that are for the library itself are relative addresses. The means for doing this for amd64 programs is relatively straightforward. amd64 offers an addressing mode known as RIP-relative. RIP-relative addressing is where you specify an offset relative to the current instruction pointer which is stored in the register %rip. 32-bit i386 programs don’t have RIP-relative addressing, so compilers have to use different tricks to for relative addressing. One of the more common techniques is to use a call +0 instruction to establish a known address. Here is the disassembly of a simple function which happens to call a global function pointer in a library.
amd64-implementation > testfunc::dis testfunc: movq +0x1bb39(%rip),%rax <0x86230> testfunc+7: pushq %rbp testfunc+8: movq %rsp,%rbp testfunc+0xb: call *(%rax) testfunc+0xd: leave testfunc+0xe: ret
i386-implementation > testfunc::dis testfunc: pushl %ebp testfunc+1: movl %esp,%ebp testfunc+3: pushl %ebx testfunc+4: subl $0x10,%esp testfunc+7: call +0x0 <testfunc+0xc> testfunc+0xc: popl %ebx testfunc+0xd: addl $0x1a990,%ebx testfunc+0x13: pushl 0x8(%ebp) testfunc+0x16: movl 0x128(%ebx),%eax testfunc+0x1c: call *(%eax) testfunc+0x1e: addl $0x10,%esp testfunc+0x21: movl -0x4(%ebp),%ebx testfunc+0x24: leave testfunc+0x25: ret
Position independent code is still really quite useful, one just has to be aware that they do pay a small price for it. In this case, we’re doing several more loads and stores. When working in intensely performance-sensitive code, those can really add up.
Per-Thread Caching: Implementation
The first problem that we needed to solve for per-thread caching was to figure out how we would store the data for the per-thread caches. While we could have gone with some of the functionality provided by the threading libraries (see threads(5)), that would end up sending us through the Procedure Linkage Table (PLT). Because we are cycle-bumming here our goal is to minimize the number of such calls that we have to make. Instead, we’ve added some storage to the ulwp_t. The ulwp_t is libc’s per-thread data structure. It is the userland equivalent of the kthread_t. We extended the ulwp_t of each thread with the following structure:
typedef struct {
size_t tm_size;
void *tm_roots[16];
} tmem_t;
Each entry in the tm_roots array is the head of one of the linked lists that we use to store a set of similarly sized allocations. The tm_size field keeps track of how much data has been stored across all of the linked lists for this thread. Because these structures exist per-thread, there is no need for any synchronization.
Why we need to know about the size of the caches
The set of caches that libumem uses for allocations only exists once umem_init() has finished processing all of the UMEM_OPTIONS environment variables. One of the options can add additional caches and another one can remove caches. It is impossible to know what these caches are at compile time. Given that this is the case, you might ask why do we want to know the size of the caches that libumem creates? Why not just create our own set of sizes that we’re going to use for honoring other allocations?
Failing to use the size of the umem caches would not only cause us to use extra space, but it would also cause us to incur additional fragmentation. Our goal is to be able to reuse these allocations. We can’t have a bucket for every possible allocation size, that would grow quite unwieldy. Let’s say that we used the same bucketing scheme that libumem uses by default. Because we have no way of knowing what cache libumem honored something from, we instead have to assume that the returned allocation is the largest possible size we can use the buffer for. If we make a 65-byte allocation that actually comes from the 80 byte cache, we would instead bucket it in the thread’s 64-byte cache. Effectively, we have to always round an allocation down to the next cache. Items that could satisfy a 64-byte allocation would end up being items that were originally 64-79 bytes large. This is clearly wasteful of our memory.
If you look at the signature of umem_free(3MALLOC) you’ll see that it takes a size argument. This means that it is our responsibility to keep track of what the original size of the allocation was. Normally malloc and free wrap this up in the malloc tags, but since we are reusing buffers, we’ll want to keep track of both the original size and the currently requested size when we reuse it. To do this, we would have to extend the malloc tag structure that we talked about above. While there are some allocations that have extra space for something like this for 64-bit programs, that is not the case for 32-bit programs. To implement it this way, that would require at another eight-byte tag be prepended to every 32-bit malloc and some 64-bit allocations as well.
Obviously this is not an ideal way to go approach the problem. Instead, if we use the cache sizes we don’t have to suffer from either of the above problems. We know that when a umem_alloc comes in, it rounds the allocation size up to the nearest cache to satisfy the request. We leverage that same idea so that when a buffer is freed we put it into the per-thread list that corresponds to the cache that it originally came from. When new requests come in we can use that buffer to satisfy anything that the underlying cache would be able to. Because of this strategy we don’t have to have a second round of fragmentation for our buffers. Similarly, because we know what the cache size is, we don’t have to keep track of the original request size. We know exactly what cache the buffer came from initially.
Following in the footsteps of trapstat and fasttrap
Now that we have opted to know about the cache sizes at run time this means that we have a few approaches we can take to generate the function that handles this per-thread layer. Remember, that we’re here because of performance. We need to cycle-bum and minimize our use of cycles. Loads and stores to and from main memory are much more expensive than simple register arithmetic, comparisons, and small branches. While there is an array of allocations sizes, we don’t want to have to always load each entry from that array. We also have another challenge. We need to avoid doing anything that causes us to use the PLT. We don’t want to end up having a call +0 instruction so we can access 32-bit PIC code. There is one fortunate aspect of the umem caches. Once they are determined at runtime, they never change.
Armed with this information we end up down a different path: we are going to dynamically generate the assembly for our functions. This isn’t the first time this has been done in illumos. For an idea of what this looks like, see trapstat. Our code functions in a very similar way. We have blocks of assembly with holes for addresses and constants. These blocks get copied into executable memory and the appropriate constants get inserted in the correct place. One of the important pieces of this is that we don’t end up calling any other functions. If we detect an error or we can’t satisfy the allocation in the function itself, we end up jumping out to the original malloc and free reusing the same stack frame.
Reaching the assembly generated functions
Once we have generated the machine code, we have the challenge of making it be what applications reach when they call malloc(). This is complicated by the fact that calls to malloc can come in before we create and initialize the new functions as part of the libumem initialization. The standard way you might solve this is with a function pointer that you swap out at some point. However, having that global function pointer causes us to need to address that in a position independent way and adds noticeable overhead. Instead we utilized a small feature of the illumos linker, local auditing, to create a trampoline. Before we get into the details of the auditing library, here’s the data we used to support the decision. We made a small and simple benchmark that just does a fixed number of small mallocs and frees in a loop and compared the differences.
#include <stdlib.h>
#include <stdint.h>
#include <stdio.h>
#include <sys/time.h>
#define MAX 1024 * 1024 * 512
int
main(int argc, char *argv[])
{
int ii;
void *f;
int size = 4;
hrtime_t start;
if (argc == 2)
size = atoi(argv[1]);
start = gethrtime();
for (ii = 0; ii < MAX; ii++) {
f = malloc(4);
free(f);
}
printf("%lld\n", (hrtime_t)(gethrtime() - start));
return (0);
}
| arch | libc (ns) | libumem (ns) | indirect call (ns) | audit library (ns) |
|---|---|---|---|---|
| i386 | 39833278751 | 57784034737 | 14522070966 | 9215801785 |
| amd64 | 32470572792 | 47828105321 | 9654626131 | 8980269581 |
From this data we can see that the audit library technique ended up being a small win on amd64, but for i386, it was a much more substantial win. This all comes down to how the compiler generated PIC code.
Audit libraries are a feature of the illumos linker that allow you to interpose on all the relocations that are being made to and from a given library. For the full details on how audit libraries work consult the Linkers and Libraries guide (one of the best pieces of Sun Documentation) or the linker source itself. We created a local auditing library that allows us to only audit libumem. As part of auditing the relocation for libumem's malloc and free symbols the audit library gives us an opportunity to replace the symbol with one of our own choice. The audit library instead returns the address of a local buffer which contains a jump instruction to the either the actual malloc or free. This installs our simple trampoline.
Later, when umem_init() runs we end up generating the assembly versions of our functions. libumem uses symbols which the auditing library interposes upon to be told where the buffers it should put the generated function are. After both the malloc and free implementations have been successfully generated, it removes the initial jump instruction and atomically replaces it with a five byte nop instruction. We looked at using both the multi-byte nop, five single byte nops, and just zeroing out the jump offset so it would become a jmp +0. Using the same microbenchmark we used earlier, we saw that the multi-byte nop made a noticeable difference.
| arch | jmp +0 (ns) | single-byte nop (ns) | multi-byte nop (ns) |
|---|---|---|---|
| i386 | 9215801785 | 9434344776 | 9091563309 |
| amd64 | 8980269581 | 8989382774 | 8562676893 |
For more details on how this all works and fits together, take a look at the updated libumem big theory statement and pay particular attention to section 8. You may also want to look at the i386 and amd64 specific files which generate the assembly.
Needed linker fixes
There are two changes that are necessary for local auditing to work correctly. Thanks to Bryan who went and made those changes and figured out the way to create this trampoline with the local auditing library.
Understanding per-thread cache utilization
Bryan worked to supply not only the necessary enhancements to the linker, but also supply enhancements to various mdb dcmds to better understand the behavior of the per-thread caching in libumem. ::umastat was enhanced to show both the amount that each thread has used and to show how many allocations each cache has in the per-thread cache (ptc).
> ::umastat
memory % % % % % % % % % % % % % % % % %
tid cached cap 8 16 32 48 64 80 96 112 128 160 192 224 256 320 384 448
--- ------- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- --- ---
1 174K 16 0 6 6 1 4 0 0 18 2 50 0 4 0 1 0 2
2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
3 201K 19 0 6 6 2 4 8 1 16 2 43 0 3 0 1 0 1
4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
5 62.1K 6 0 8 7 3 9 0 0 13 5 38 0 6 0 2 1 0
6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
cache buf buf buf buf memory alloc alloc
name size in use in ptc total in use succeed fail
------------------------- ------ ------- ------- ------- ------- --------- -----
umem_magazine_1 16 33 - 252 4K 35 0
umem_magazine_3 32 36 - 126 4K 39 0
umem_magazine_7 64 0 - 0 0 0 0
umem_magazine_15 128 4 - 31 4K 4 0
umem_magazine_31 256 0 - 0 0 0 0
umem_magazine_47 384 0 - 0 0 0 0
umem_magazine_63 512 0 - 0 0 0 0
umem_magazine_95 768 0 - 0 0 0 0
umem_magazine_143 1152 0 - 0 0 0 0
umem_slab_cache 56 46 - 63 4K 48 0
umem_bufctl_cache 24 153 - 252 8K 155 0
umem_bufctl_audit_cache 192 0 - 0 0 0 0
umem_alloc_8 8 0 0 0 0 0 0
umem_alloc_16 16 2192 1827 2268 36K 2192 0
umem_alloc_32 32 1082 921 1134 36K 1082 0
umem_alloc_48 48 275 202 336 16K 275 0
umem_alloc_64 64 487 359 504 32K 487 0
umem_alloc_80 80 246 234 250 20K 246 0
umem_alloc_96 96 42 41 42 4K 42 0
umem_alloc_112 112 741 676 756 20K 741 0
umem_alloc_128 128 133 109 155 20K 133 0
umem_alloc_160 160 1425 1274 1425 36K 1425 0
umem_alloc_192 192 11 9 21 4K 11 0
umem_alloc_224 224 83 82 90 20K 83 0
umem_alloc_256 256 8 8 15 4K 8 0
umem_alloc_320 320 24 22 24 8K 24 0
umem_alloc_384 384 7 6 10 4K 7 0
umem_alloc_448 448 20 19 27 12K 20 0
umem_alloc_512 512 1 - 16 8K 138 0
umem_alloc_640 640 0 - 18 12K 130 0
umem_alloc_768 768 0 - 10 8K 87 0
umem_alloc_896 896 0 - 18 16K 114 0
...
In addition, this work inspired Bryan to go and add %H to mdb_printf for human readable sizes. As a part of the support for the enhanced ::umastat, there are also new walkers for the various ptc caches.
Performance of the Per-Thread Caching
The ultimate goal of this was to improve our performance. As part of that we did different testing to make sure that we understood what the impact and effects of this would be. We primarily compared ourselves to the libc malloc implementation and a libumem without our new bits. We also did some comparison to other allocators, notably eglibc. We chose eglibc because that is what the majority of customers coming to us from other systems are using and because it is a good allocator, particularly for small objects.
Tight 4 byte allocation loop
One of the basic things that we wanted to test, inspired in part by some of the behavior we had seen in applications, was to measure what a tight malloc and free loop of a small allocation looked like where we varied the number of threads. Below we included a test where we did this one thread and one where we did it with sixteen threads. The main take away we got from this is that libumem has historically been slow at these compared to a single threaded libc program. The sixteen thread graph shows why we really want to use libumem compared to libc. The graph shows the time per thread. As we can see, libc's single mutex for malloc is rather painful.
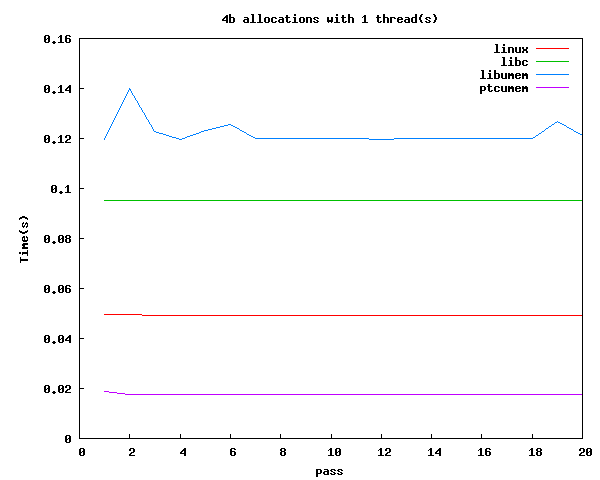
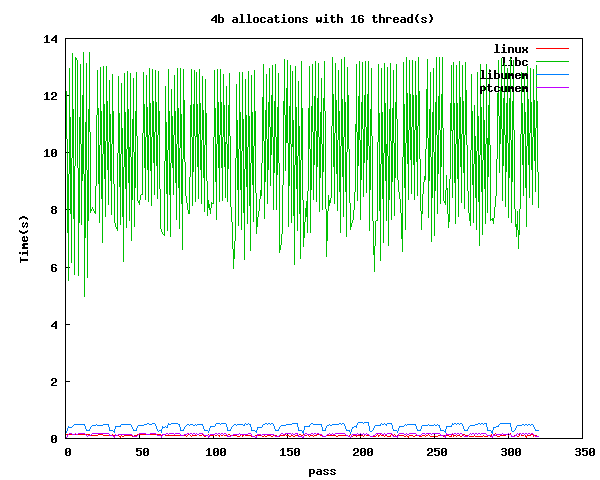
Time for all cached allocations
Another thing that we wanted to measure was how our allocation time scaled with the size of the cache. While our assembly is straightforward, it could probably be further optimized. We ran the test with both 32-bit and 64-bit code and the results are below. From the graphs you can see that scale fairly linearly across the caches.
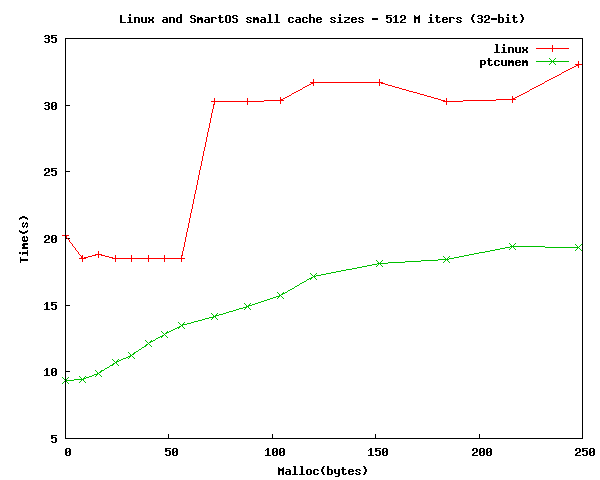
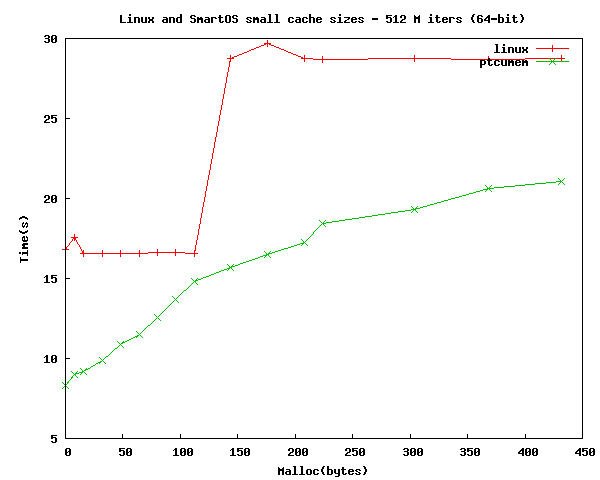
The effects of the per-thread cache on uncacheable allocations
One of the things that we wanted to verify was that the presence of the per-thread caching did not unreasonably degrade the performance of other allocations. To look at this we compared what happened if you used libumem and what happened if you did not. We used pbind to lock the program to a single CPU, measured the time it took to do 1KB sized allocations, and compared the differences. We took that value and divided by the total number of allocations we had performed, 512 M in this case. The end result was that for a given loop of malloc and free, the overhead was 8-10ns. That was within reason for our acceptable overhead.
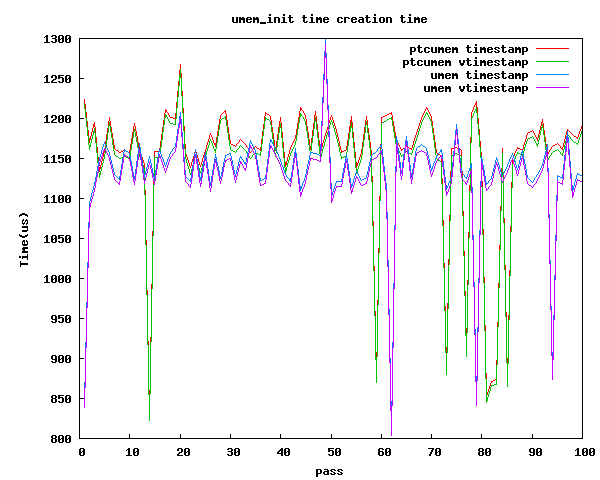
umem_init time
Another one of the areas we wanted to make sure that we didn't seriously regress was the time it takes umem_init. I've included a coarse graph that was created using DTrace. I simply rigged up something that traced the amount of wall and cpu time umem_init took. We repeated that 100 times and graphed the results. The graph below shows a roughly 50 microsecond increase in the wall and cpu time. In this case, a reasonable increase.
Our Original Flame Graph
The last thing that I want to look at is what the original flame graph now looks like using per-thread-caching. We increased the per-thread cache to 64MB because that allows us to cache the majority of the malloc activity which primarily comes from only one thread. The new flame graph is different from the previous two. The amount of time that we've spent in malloc and free has been minimized and compared to libumem previously, we are no longer three layers deep. In terms of raw improvement, while this normally took around 110 seconds with libc, with per-thread-caching we're down to around 78 seconds. Remember, this is a pure node.js benchmark. To have an improvement to malloc() result in a ~30% win was pretty surprising. Even in dynamic garbage collected languages, the performance of malloc is still important.

Wrapping Up
In this entry I've described the high-level design, implementation, and some of the results we've seen from our work on per-thread caching libumem. For some workloads there can be a substantial performance improvement by using per-thread caching. To try it out, grab the upcoming release of SmartOS and either add -lumem to your Makefile or simply try it out by running your application with LD_PRELOAD=libumem.so.
When you link with libumem, per-thread caching is enabled by default with a 1 MB per-thread cache. This value can be tuned via the UMEM_OPTIONS environment variable via UMEM_OPTION=perthread_cache=[size]. For example, to set it to 64 MB, you would do something like: UMEM_OPTIONS=perthread_cache=64M. If you enable any kind of the umem_debug(3MALLOC) facilities then this will be disabled. Similarly if you request nomagazines, this will be disabled.
If you have questions, feel free to ask here or join us on IRC.